


Partial Sum Accumulation algorithm
Suma de vecinos en espacio de hamming en tiempo lineal, Linear-time neighbor summation in hamming space

Contexto. En este post presento el algoritmo PSA (acumulación de sumas parciales), una generalización del algoritmo que usamos para resolver la quiniela. PSA logra una reducción significativa de la complejidad frente al enfoque naive/trivial, razón por la cual chatgpt cree que podría haber algo novedoso y me ha animado a publicarlo. Mi formación en mates es justita así que lo desconozco. Pero igualmente me parece un post chulo. Pásale esto a tu colega el matemático y que nos saque de dudas.
Todo el código utilizado para el post está en google colab y github.
El problema
Juguemos a un juego. El juego consiste en lanzar una moneda 2 veces y un dado 1 vez. Todos los posibles resultados de este juego generan lo que los matemáticos creo que llaman un espacio de hamming. En este juego el espacio tendría 3 dimensiones. La primera dimensión tendría 2 posibles elementos, la segunda otros 2 y la tercera 6. Por tanto este espacio de hamming tendría un total de 24 puntos (2*2*6).
A cada punto del espacio podemos asociarle un valor por ejemplo la probabilidad de que ocurra dicho combinacion de sucesos (imaginemos que moneda y dado están trucados de forma conocida para que cada suceso no sea equiprobable).
Supongamos ahora que podemos hacer un pronóstico, por ejemplo CC1 (cara, cara, 1) y ganamos si fallamos como mucho 1 dimensión (acertar al menos 2 dimensiones). Entonces la probabilidad de ganar pronosticando el punto P será igual a la suma de las probabilidades de todos los puntos cuya distancia de hamming hasta P sea <=1. En otras palabras, debemos sumar la probabilidad de P (distancia=0) y de todos los puntos que se diferencien en 1 dimensión de P (distancia=1): CC1+XC1+CX1+CC2+CC3+CC4+CC5+CC6
Notación y resumen
Diremos que un espacio de hamming es completo si todas las combinaciones de los posibles elementos de cada dimensión están definidas, es decir si tienen un valor asociado.
Diremos que un espacio de hamming es simétrico si todas las dimensiones tienen el mismo número de posibles elementos.
El código que voy a presentar no necesita que el espacio de hamming sea simétrico pero sí necesita que sea completo. Afortunadamente un espacio de hamming no completo se puede transformar en uno completo simplemente estableciendo en 0 el valor de los puntos no definidos.
En espacios simétricos para cada punto P el número de vecinos a distancia menor o igual que r (y por tanto la cantidad de sumas que debe hacer el algoritmo trivial) es el resultado de esta expresión:
Y esta es la expresión que indica la cantidad de elementos que deberá sumar el algoritmo PSA:
d: número de dimensiones
q: número de elementos posibles por dimensión
r: distancia hasta la que sumar
Como vemos en espacios simétricos la complejidad del algoritmo PSA aumenta de forma lineal con respecto a las tres variables involucradas. Para espacios no simétricos las expresiones son más complicadas pero la eficiencia comparada del algoritmo PSA es todavía mayor ya que puede ahorrar sumas en las dimensiones más grandes si le pasamos un array q ordenado (como comentaremos después).
En esencia, el algoritmo PSA consigue esta reducción de complejidad aprovechando los solapamientos: dados 2 puntos A y B, y sus vecinos a sumar N(A) y N(B), es posible que exista un subconjunto de puntos que pertenezca tanto a N(A) como a N(B) y por tanto, pueda sumarse ese subconjunto solo una vez y reutilizar el cálculo para el otro punto. El algoritmo PSA, al hacer los cálculos de forma matricial para todo el espacio, explota automáticamente todos estos solapamientos.
Cabe resaltar que estas expresiones indican la cantidad de sumas que deberá hacer cada algoritmo *por elemento o punto del espacio*. Para calcular la suma de los vecinos de todo el espacio habría que multiplicar por el número total de puntos en el espacio (q^d para el caso de espacios simétricos).
Implementación en código
Empecemos creando un array de enteros q. Este array define totalmente la estructura de nuestro espacio. Cada elemento del array representa el número de elementos posibles en esa dimensión. El número de elementos del array es el número de dimensiones. Además como luego en el código los valores de asociados a cada punto los pasaremos en un array aplanado en 1D llamado 'space', el orden de q nos servirá para saber cómo ha sido aplanado el array y poder acceder a los valores correctamente.
Así las funciones solo necesitarán 3 inputs:
space: los valores asociados a cada punto
q: número de elementos por dimensión
r: distancia hasta la que sumar
Por lo explicado pueden observarse las 2 restricciones:
prod(q) = len(space) // la cantidad de valores que contiene space debe ser el producto de q
0 <= r <= len(q) // la distancia hasta la que sumar debe estar entre 0 y d
Además q nos va a indicar el orden que sigue space, los últimos elementos de q harán referencia a las dimensiones más ‘profundas’ de space. Es decir, que pasándole un mismo space, el algoritmo sumará unos valores u otros según cómo le pasemos q.
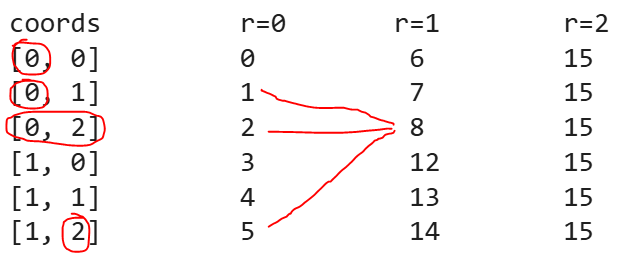
En este ejemplo con valores del 0 al 5, esto es lo que el algoritmo entiende según qué q le pasemos. Fijaos en el punto con valor 4 con respecto al primer punto. En el primer caso se correspondería con el [1,1], así que está a distancia 2 con respecto al [0,0]. Pero en el segundo caso se corresponde con [2,0] y está a distancia 1. Por tanto si le pedimos que nos sume vecinos hasta distancia r<=1, en un caso en punto con valor 4 será un vecino a sumar pero en el otro no.

Lógicamente podemos pasar q en el orden que queramos si hacemos también la transformación adecuada al orden de los valores de space.
Algoritmo naive
Lo primero que vamos a hacer es crear un pequeño objeto al que con mucho ingenio llamaremos ‘base’. Base va a contener algunos valores precalculados únicamente dependientes de q. Estos valores nos van a indicar cuánto debemos sumar o restar a los índices de space. Por ejemplo en el caso anterior (q=[2, 3]), para aplicar una diferencia en la primera dimensión debemos sumar o restar 3 al índice. Y para aplicar una diferencia en la segunda dimensión debemos sumar o restar 1 o 2.
Así por ejemplo, para el caso de la quiniela donde q es un array de 14 elementos en el que todos son 3, esta sería la base:

Para el algoritmo naive necesitamos anidar r bucles. Como no conocemos el valor de r a priori, la forma más clara de hacer esto es con llamadas recursivas.

Cuando r=1 se va por el bucle de abajo, calcula las diferencias para cada dimensión i y suma los valores correspondientes.
Si r>1, calcula también las diferencias para cada dimensión pero en lugar de acceder a los valores se llama a sí misma con el nuevo índice para volver a ejecutar un bucle que empiece en siguiente dimensión.
Ejecutando esta función para cada punto con r=1 y r=2 (r=0 es igual a space) nos sale esto:
Transformación básica para algoritmos matriciales
El algoritmo naive se puede implementar de forma más eficiente haciendo las operaciones de forma matricial (calcular los vecinos de todos los puntos a la vez). En términos algorítmicos sería lo mismo pero supongo que hace las operaciones a más bajo nivel, reduce asignaciones de memoria, punteros, contadores, etc y por eso consigue reducir tiempos.
Para trabajar de forma matricial necesitamos una función que nos aplique una diferencia en la dimensión i para todo space. Esta es la implementación que he elegido (y que utilizaremos también para el algoritmo PSA):
def apply_diff(space, g, j):
aux=space.reshape(-1, g)
aux=np.roll(aux, j, axis=1)
return aux.flatten()reshape restructura el array en 2D haciendo grupos de g elementos
roll coge los últimos j elementos de cada grupo y los pone al principio del grupo
flatten vuelve a aplanar el array a 1D
El resultado es este:

Como podemos ver se consiguen alinear las diferencias. T(6,3) por ejemplo alinea cada punto con el punto con el que difiere en la dimensión 1. Y T(3,1) y T(3,2) hacen lo propio con las 2 formas de diferenciarse en la dimensión 2. Ya solo falta sumar esas 4 matrices horizontalmente y obtendríamos la suma de vecinos hasta r<=1.
Esta implementación no es probablemente la más eficiente. Para la quiniela tengo en javascript una con bucles que funciona más rápido. Entiendo que controlar los índices para acceder de manera apropiada a los elementos tiene menos impacto en el performance que restructurar y reordenar los elementos del array. En cualquier caso creo que esta es la implementación más clara/didáctica.
Lógicamente para hacer esta transformación no vamos a utilizar g y j sino los coeficientes que hemos precalculado en ‘base’, le pasaremos base y un indicador de la dimensión a la que queremos aplicar diferencia.
Lo importante de cara al PSA. Esta transformación T, tal y como la hemos definido (g y j son necesariamente coeficientes de ‘base’ que siguen cierta lógica), tiene 2 propiedades:
T(T(space, d1), d2) = T(T(space, d2), d1)
T(space1, d) + T(space2, d) = T(space1+space2, d)
Es decir, podemos aplicar diferencias en dimensión 1 y al resultado diferencias en dimensión 2, o al revés. Igualmente podemos aplicar diferencias en dimensión d al array1, luego al array2, y luego sumar los resultados, o podemos sumar primero array1+array2 y al resultado aplicarle diferencias en d.
Esto nos ayudará a ahorrar operaciones. Caso base para ilustrar. Estas son las sumas que tendríamos que hacer para sumar hasta distancia 2 un espacio de 3 dimensiones binarias:
Nnaive = s + T(s, 1) + T(s, 2) + T(s, 3) + T(T(s, 1), 2) + T(T(s, 1), 3) + T(T(s, 2), 3)
Estaríamos sumando 7 elementos (6 sumas). Sin embargo si creamos una variable auxiliar y aprovechamos las propiedades comentadas podemos hacerlo sumando 5 elementos (4 +1 sumas):
A = T(s, 1) + T(s, 2)
Npsa = s + A + T(s, 3) + T(T(s, 1), 2) + T(A, 3)
Algoritmo naive matricial
Utilizando esa transformación la implementación del algoritmo naive matricial podría ser prácticamente igual que la naive por elemento, simplemente cambiando los accesos a elementos de space por operaciones de suma de matrices:

Algoritmo PSA
La implementación del PSA queda a mi juicio más elegante. Sorprende que salga anidando solo 2 bucles: uno para las distancias y otro para las dimensiones.
La q hace el ‘acordeón’ de forma inmediata. Es decir, aunque haya más de una forma de diferenciarse en cierta dimensión (q>2), todas las formas se suman en cuanto se calculan (en lugar de abrir nuevas rutas de transformación) ya que a todas ellas se les va a aplicar la misma estructura de sumas y transformaciones.

La clave para entender el código creo que está en visualizar qué es lo que almacena ‘acum’ en cada momento en términos de las transformaciones comentadas.
En primer lugar, ‘tile’ lo que hace es crear un array con tantas copias de space como dimensiones tenga nuestro espacio. Luego el bucle interno irá actualizando el contenido de cada elemento de acum, aplicándole la trasformación para la dimensión correspondiente y acumulando las matrices resultantes.
Por ejemplo, esto es lo que contendrá acum tras cada iteración de n para el caso de 3 dimensiones y a distancia <=3.

En amarillo he señalado los valores que se añaden a ‘sum’ (la variable que retorna). Si nos fijamos, las celdas en amarillo se corresponden con la suma de vecinos a distancias 1, 2 y 3 respectivamente. Dado que cada celda solo depende de la de arriba y la de su izquierda, si solo quisiésemos sumar las distancias a exactamente r podríamos adaptar el algoritmo reduciendo algunos cálculos.
Consideraciones finales
Intuyo que ceteris paribus las transformaciones en las dimensiones más ‘profundas’ (últimos elementos de q) son algo más costosas. Por eso he implementado el algoritmo y la creación de ‘base’ de tal forma que haga estas transformaciones en primer lugar (y así sea estas las que haga menos veces).
Por la misma razón, en caso de espacios no simétricos (dimensiones con q distinto), PSA podrá tener una ganancia extra de eficiencia si se le pasa un q ordenado de forma creciente (y pérdida de eficiencia si q decreciente), es decir si space se aplana de tal forma que las dimensiones más profundas sean las que tienen un q mayor.
Por último, existen algunos casos en los que si sabemos cómo han sido calculados los valores de space podemos conseguir la suma de vecinos de una forma aun más eficiente acumulando las sumas en la propia creación. Yo suelo referirme a él como el enfoque de las cajitas. Y se podría aplicar por ejemplo al problema con el que he empezado el post si los eventos de cada dimensión son sucesos independientes. No obstante este algoritmo no sirve si los valores de space son arbitrarios o han sido calculados mediante procesos complejos. En cualquier caso lo dejo por aquí para los curiosos.

Pd1. Puedes ver todos mis posts agrupados por temática en el Índice.
Pd2. Posts relacionados: Descifrando el Numble, Wordle: estrategia óptima, 10 enfoques para ganar en juegos de azar.