


3 formas de conseguir datos

Soy un poco friki. A veces me hago preguntas de lo más variopintas. Me tiro una semana obsesionado con un tema en realidad irrelevante (ejemplo estrategia óptima del wordle, optimizar oposiciones o kriptotesoro). E intentando encontrar la respuesta termino aprendiendo cosas que muchas veces me son útiles en otros contextos.
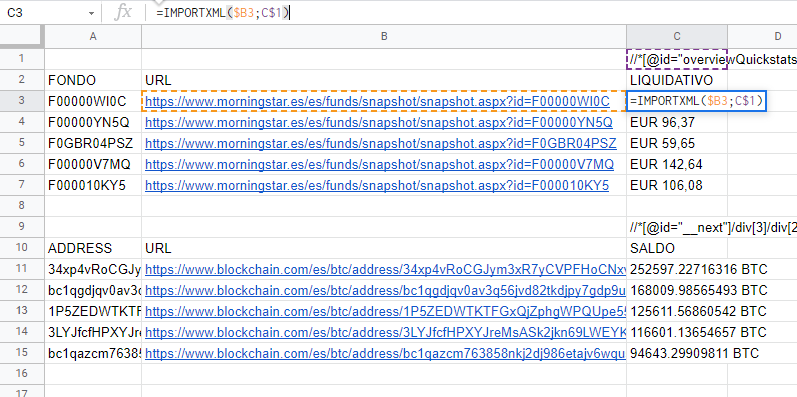
Quise montar una tabla de liquidativos de fondos y descubrí los import de googlesheets.
O quise saber cuántos planes de pensiones hay en españa y qué coste o rentabilidad tienen y aprendí a usar la pestaña network del navegador.
O quise relacionar los costes de los fondos con su active share y su rentabilidad a largo plazo y entendí que algunas consultas llevan headers (y cómo simularlas).
En este post voy a contar estos 3 puntos con ejemplos. Aunque son útiles para conseguir datos de cualquier web, usaremos de sparring a morningstar. Este es el googlesheets que voy a utilizar para los ejemplos. ¡Al lio!
1. Funciones import
Los import de googlesheets son muy útiles. El que más uso ahora es IMPORTXML. Le metes una URL y la ruta XPath al dato que quieres y listo.
Con esto puedes por ejemplo sacar todos los liquidativos a partir de una lista de códigos morningstar o ver cuántos btc hay en una lista de addresses.
Para conseguir la ruta XPath lo más sencillo es inspeccionar elemento -> click derecho -> copy xpath.

Otra de las import que te puedes mirar es la función IMPORTHTML. Esta es útil si por ejemplo quieres cargar una tabla.
2. Pestaña network
Las funciones anteriores tienen un problema. Cada una de ellas, es decir, cada celda, implica una llamada, una petición. Y esto puede traer problemas. Lo suyo sería buscar la forma de conseguir todos los datos de una para no sobrecargar ni a la página en cuestión ni a google. Pero para eso tendremos que encontrar el origen y atacar a la base de datos.
Afortunadamente en morningstar hay un buscador (uno de fondos y otro de planes de pensiones). ¿Y de dónde saca los datos el buscador? Pues vamos a verlo.
Si inspeccionamos elemento, en la pestaña network podemos ver las peticiones que va haciendo la web. Solo tenemos que forzar que se actualice algún dato y ya tenemos ahí el origen de datos.

Y, oh sorpresa, si abrimos ese origen en otra pestaña nos devuelve un json con todos los fondos.
Y, oh sorpresa, la ruta del origen contiene un parámetro que se llama "pageSize". Me pregunto que pasará si añadimos 3 o 4 ceros a ese 50... Spoiler, sí, nos devuelve toda la base de datos. Había 1.038 planes de pensiones y 46.507 fondos la última vez que lo comprobé.

Nota a pie: para parsear un json pasar un json a tabla lo más cómodo es copiarlo en un bloc de notas, abrir un excel y darle a datos -> obtener datos -> de un archivo -> de json.
3. Consulta con headers
El método anterior tiene un problema. A veces la url origen nos devolverá error 401, error de autenticación (por ejemplo, intentando pillar el active share de la pestaña cartera). Pero a ver, si estamos cogiendo un dato en modo usuario y no hemos metido login ni nada, pues tenemos que poder.
Una solución fácil pasa por emular la petición en googlescript añadiéndole ese parámetro auth (para ver el código asociado a un libro: extensiones -> apps script).

Vale, ¿y de dónde sacamos ese chorizo? Pues lo copiamos a pelo del inspector (desde network, seleccionando la consulta que queremos).

Y listo, tenemos nuestra petición operativa para usarla desde cualquier celda.

Venga, para cerrar el post os dejo una lista y una gráfica.
La lista de los fondos más caros según morningstar.

Y la gráfica, para una panorámica más general.
